MSSQL Server는 기본적으로 클라이언트(Client)-서버(Server) 아키텍처이다.
SQL Server의 프로세스(Process)는 클라이언트 응용 프로그램(Application)이 요청(Request)을 보내는 것으로 시작된다.
이 요청은 SQL Server와 클라이언트 간에 연결된 네트워크 인터페이스(Network Interface)를 통해 들어온다.
SQL Server는 처리된 데이터를 가지고 수락(Acceptance), 처리(Processing) 및 응답(Response)한다.
SQL Server의 아키텍처를 보자면, 아래 그림과 같다.
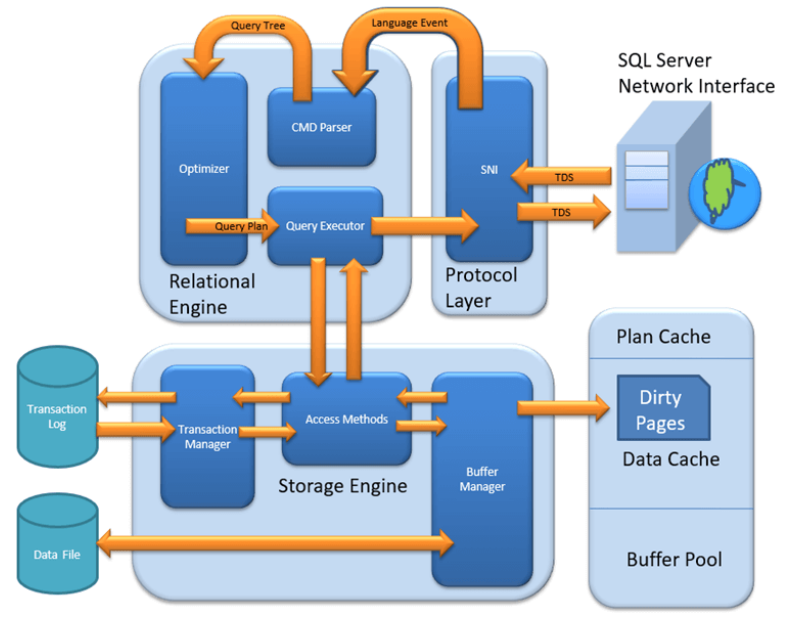
SQL Server의 다이어그램을 통해 본다면 크게 3가지의 주요 모듈로 이루어져있다.
- Protocol Layer
- Relational Engine
- Storage Engine
다이어그램은 주로 SQL Server의 핵심 기능이 어떻게 유기적으로 결합하여 동작하는 지에 대해 알고 싶을 때 보기 좋다.
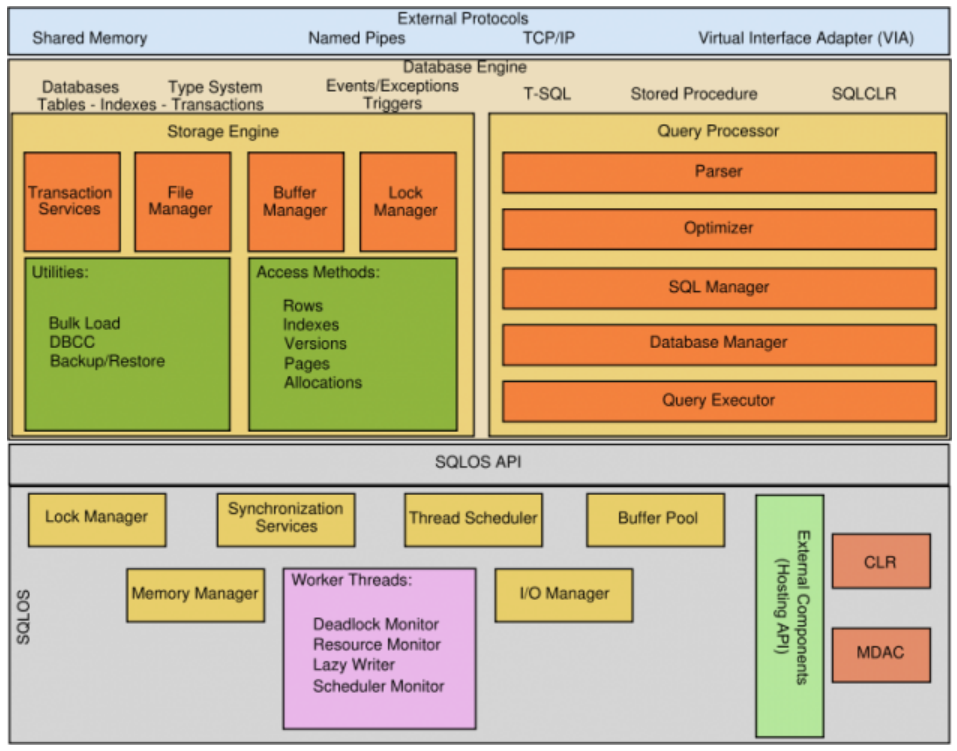
Physical 아키텍처는 실제 SQL Server를 구성하고 있는 아키텍처로, 세부 기능들이 어떤 식으로 분류되어 있으며, 각각의 분리된 역할을 알고 싶을 때 보기 좋다.
우선 다이어그램의 화살표를 따라가며 SQL Server의 핵심 기능이 어떤 식으로 동작하는 지에 대해 공부하고, 이를 중간 중간 Physical 아키텍처와 매칭하여 세부 기능들의 동작 방식까지 알아보도록 하자!
먼저 다이어그램 상의 Protocol Layer 먼저 알아보도록 하자.
Protocol Layer는 Physical 아키텍처에서 External Protocols 에 해당한다고 볼 수 있다.
External Protocols
우선 클라이언트(응용 프로그램)와 SQL 서버 간에 통신할 때에는 'TDS' 라는 프로토콜(메시지)을 사용한다.
- TDS
Tabular Data Stream Protocol을 말하는데, 이는 응용 프로그램 계층의 Reqeust/Response 프로토콜로, 응용 프로그램과 DB 서버 간의 상호작용(쿼리 요청(Bulk Insert 포함), 프로시저 동작, RPC(Remote Procedure Call), 데이터 반환, 트랜잭션 매니저 Request 등)을 용이하게 하고, 인증(Authentication) 및 채널 암호화 협상(Channel Encryption Negotiation) 기능을 제공하기도 한다. 어떻게 보면 프로토콜이라 할 수도 있고, 아닐 수도 있는데, TCP/IP와 같은 프로토콜 내에 캡슐화되어 내장되는 형식이므로, predefine 된 메시지라고 보는 것이 좀 더 정확할 수 있겠다.
참고) TDS는 마이크로소프트의 독점적인 기술이기 때문에, 윈도우 외의 환경에서는 TDS를 사용할 수 없다!
"TDS라는 자동차(메시지)가 갈 수 있는 길(프로토콜, 통신방식)은 Shared Memory / Named Pipes / TCP/IP / VIA(Virtual Interface Adapter) 가 있다!"
- Shared Memory (공유 메모리)
SQL Server를 로컬 환경으로 구성하였을 때, (공유 메모리 프로토콜 사용을 임의로 해제해 놓지 않는 이상) 로컬에서 SQL Server 인스턴스에 연결하는 기본적인 프로토콜이다.
SSMS에서 이 프로토콜을 사용하는 [서버 이름]에 해당하는 옵션은
"." / "localhost" / "127.0.0.1" / "Machine/Instance" 가 있다.
- Named Piepes (명명된 파이프(?))
클라이언트와 서버가 동일한 LAN에 있을 때 사용되는 프로토콜로, 기본적으로 TCP 445 포트를 사용한다. 때문에 TCP/IP 프로토콜이 없는 환경에서는 사용할 수 없다.
SSMS 상에서 기본적으로 Disabled로 되어있으며, 활성화(Enable) 했을 때 사용 가능하다.
- TCP/IP
가장 보통의 환경, IP 주소 및 포트를 통해 통신하는 프로토콜이다.
SSMS에서 이 프로토콜을 사용하는 [서버 이름]에 해당하는 옵션은
"서버컴퓨터이름/인스턴스" 이다. ex) SERVER_SQL/SQL_MS
- VIA
뭔지 잘 모르겠다. SQL Server 2012 이후로 Deprecated 되었다...!
다음은 Relational Engine에 대해 알아보자. 다이어그램상의 Relational Engine에 있는 모듈들은 모두 Physical 아키텍처상의 Query Processor에 포함된다.
Query Processor
- (CMD) Parser
클라이언트로부터 쿼리 데이터를 수신하는 관계형 엔진의 첫 번째 구성요소로,
구문 및 의미 오류에 대한 쿼리를 확인하여 'Query Tree'를 생성하는 모듈이다.
1. 구문(Syntactic) 검사 - 사용자(User) 입력이 MS SQL 구문 또는 문법 규칙을 따르지 않으면 오류를 반환하는 과정
ex) SELCET * FROM <Table Name>;
=> 'SELCET' 라는 키워드는 MS SQL에 존재하지 않는다. ('SELECT' 가 올바른 것.)
2. 의미(Semantic) 검사 - 노멀라이저(Normalizer)에 의해 수행되며, 조회 중인 Column명, Table명이 스키마에 존재하는지 확인하는 과정. 존재하는 경우 쿼리에 바인딩(Binding)한다고 한다.
ex) SELECT * FROM USER_ID;
=> 'USER_ID' 라는 테이블이 존재하지 않는다면, 노멀라이저가 찾지 못하여 오류 메시지를 표시한다.
3. Query Tree 생성 - 쿼리가 순서에 맞게 실행되게끔 하는 트리형 자료구조를 생성한다.
- Optimizer
사용자 쿼리에 대한 실행 또는 계획을 만드는 역할로, DML(Data Modification Language) - SELECT, INSERT, DELETE, UPDATE 등의 명령에 대한 최적화가 수행된다. MS SQL의 옵티마이저는 내장된 Exhaustive/Heuristic 알고리즘으로 작동하여 쿼리 실행 시간을 최소화하는 것을 목표로 한다. 구체적인 알고리즘은 마이크로소프트의 비밀사항이다. 대략적으로 세 단계에 걸쳐 최적화가 진행된다.
0단계 (Phase 0) : 일반적인 계획 검색
- 사전 최적화 단계
- 일반적으로 많이 사용되는 실용적이고 실행가능한 Plan을 우선적으로 검색
=> 굳이 필요하지 않은 최적화 Plan을 찾는 데에 추가 비용을 발생시키지 않게끔 함.
- 어떠한 Plan도 찾을 수 없는 경우 1단계(Pahse 1)를 시작
1단계 (Phase 1) : 트랜잭션 처리 탐색 Plan
- 단순, 복합 Plan 검색이 포함된다.
- 단순 Plan 검색 : 쿼리와 관련된 컬럼 및 인덱스의 과거 데이터를 통계 분석에 사용.
- 복합 Plan 검색 : 다중 인덱스를 포함.
2단계 (Phase 2) : 병렬 처리 및 최적화
- 0단계, 1단계 중 어느것도 작동하지 않는 경우 실행
- 병렬 처리 가능성을 검색하는 단계이며, 기계의 처리능력과 구성에 따라 달라짐
- 이 단계도 가능하지 않은 경우, 최종 최적화 단계가 실행되는데, 이 최종 최적화 단계 알고리즘이 마이크로소프트의 비밀사항이다.
- Query Executor
Storage Engine의 Access Method를 호출하는 역할이다. 또한 쿼리문 실행에 필요한 데이터를 불러오는 로직에 대한 실행 plan을 제공한다. Storage Engine으로부터 데이터를 받으면, 프로토콜 계층으로 해당 데이터를 결과로서 반환한다.
다음은 Storage Engine에 대하여 살펴보자.
Storage Engine
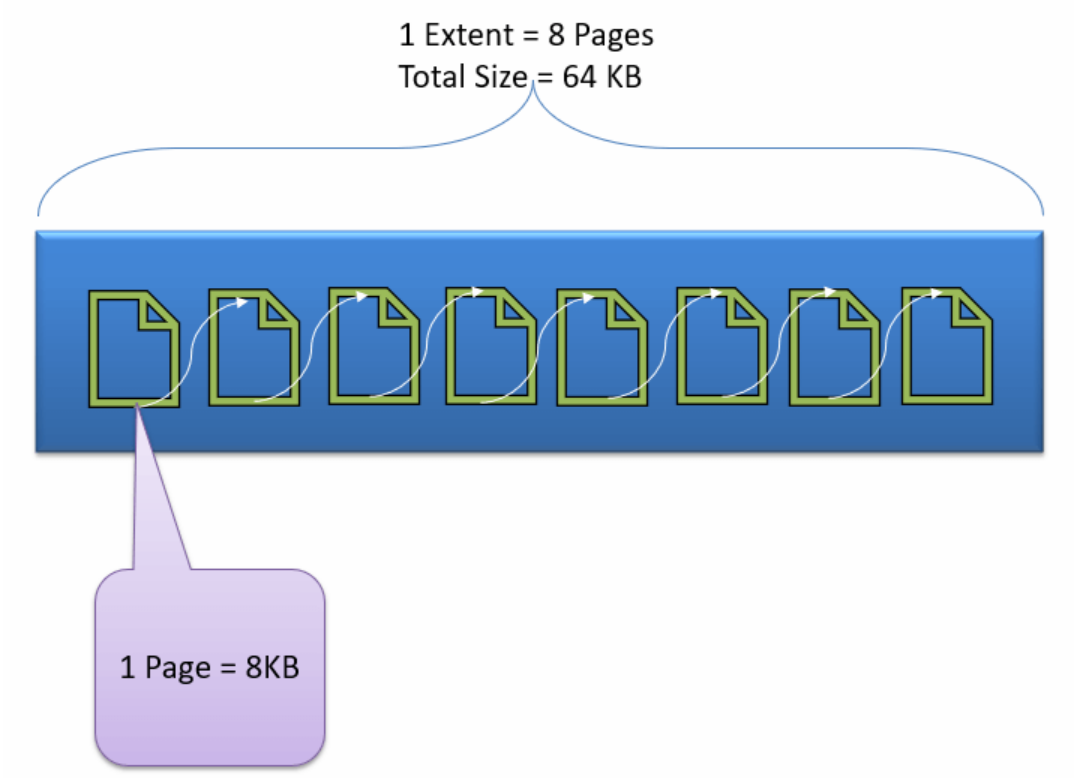
MS SQL에서 데이터 파일은 Page라는 단위로 저장되며, 이는 SQL Server의 기본적인 I/O 단위이고, Page 하나당 크기는 8 KB이다. (다른 DBMS에서는 보통 기본 단위를 Block이라 칭한다.) 이러한 Page들은 8개씩 논리적으로 묶여 Extent(익스텐트)를 형성한다. 이와 관련된 자세한 내용은 https://co-no.tistory.com/9 를 참고하길 바란다!
- Access Method
Query Executor와 Buffer Manager, Transaction Logs 사이에서 인터페이스 역할을 한다. Access Method 자체만으로는 아무 일도 할 수 없으며, 주요 기능은 쿼리가 Select 문인지 아닌지를 판단하는 것이다.
Select 문인 경우 Buffer Manager로 쿼리를 전송하고,
Select 문이 아닌 경우, Transaction Manager로 쿼리를 전송한다.
- Buffer Manager
Buffer Manager는 Plan Cache, Data Parsing, Dirty Page 모듈의 핵심 기능들을 관리한다.
- Plan Cache - Buffer Manager가 Execution Plan이 Plan Cache에 저장되어 있는지 확인
1) Execution Plan이 존재하는 경우
Plan Cache 및 이와 연계된 Data Cache의 쿼리 Plan이 사용된다.
2) Execution Plan이 존재하지 않는 경우
해당 Execution Plan이 첫 케이스여서 존재하지 않는다면 해당 Plan을 실행하고 Plan Cache에 새로 저장한다. - Data Parsing : Data cache or Data storage - Buffer Manager가 필요한 데이터에 대한 Access를 제공한다.
1) Data cache에 데이터가 존재한다면? Soft Parsing
먼저 Buffer Manager가 Data cache 속 버퍼에 데이터가 존재하는지 확인한다. 데이터가 존재한다면, 이 데이터가 Query Executor로 전달되어 사용된다. 이런 방식을 사용하는 이유는 데이터 파일이 저장되어 있는 Disk에까지 접근을 하지 않으므로, Disk I/O 연산을 줄일 수 있다.
2) Data cache에 데이터가 존재하지 않는다면...? Hard Parsing
만약 Data Cache 속 버퍼에 데이터가 존재하지 않는 것으로 확인될 경우, Buffer Manager가 Disk에 저장되어 있는 Data file에 접근한다. - Dirty Page - Transacntion Manager의 로직 처리의 결과로 생긴다. 페이지가 메모리에 처음으로 읽혀 들어오면 이는 메모리에 있는 데이터 페이지와 Disk에 있는 데이터 페이지의 내용이 동일하기 때문에 Clean Page라고 부른다. 그러나, 페이지가 수정이 되면 메모리에 있는 데이터 페이지의 내용과 Disk에 있는 것과는 달라지기 때문에 이를 Dirty Page 라고 부른다.
Buffer Manager가 작업 스레드의 읽기 요청을 받으면 Data Cache의 64 페이지 목록을 가져와 사용 가능한 Buffer 목록이 특정 임계 값 미만인지 여부를 확인하여, 임계값 미만일 경우에는 목록에 있는 Dirty page를 Disk에 기록하게 된다.
- Transaction Manager
Transaction Manager는 Access Method에서 Select 문이 아닌 경우에 호출되는 모듈로, Log Manager와 Lock Manager 로 이루어져 있다.
- Log Manager
Transaction Log 를 통해 시스템에서 수행된 모든 업데이트 로그들을 기록한다.
이때 로그에는 Trasaction ID가 포함되어 있는 Sequence Number와 데이터 수정 레코드(Data Modification Record)가 존재한다. 이 트랜잭션 로그는 커밋된 트랜잭션과 트랜잭션 롤백에 대하여 기록하기 위함이다. - Lock Manager
트랜잭션 수행 중에는 Data Storage와 관련된 데이터들은 Lock(잠금) 상태에 들어가는데, 이러한 프로세스가 Lock Manager에 의해 수행된다. 이러한 프로세스 덕에 일관성(Consistency)* 및 독립성(Isolation)*이 보장될 수 있다.
* 일관성(Consistency) : 트랜잭션이 실행을 성공적으로 완료하면 언제나 일관성 있는 DB 상태로 유지하는 것을 의미.
* 독립성(Isolation) : 트랜잭션을 수행 시 다른 트랜잭션의 연산 작업이 끼어들지 못하도록 보장하는 것을 의미.
참조
SQL Server 아키텍쳐(Architecture)
MS SQL Server는 클라이언트-서버 아키텍처이다. MS SQL Server 프로세스는 클라이언트 응용 ...
blog.naver.com
https://dbtut.com/index.php/2019/08/20/sql-server-architecture/
SQL Server Architecture - Database Tutorials
In this article I will describe SQL Server Architecture. In the article, I will proceed through the
dbtut.com
https://kenial.tistory.com/341
SQL Server의 통신 프로토콜, TDS
SQL 서버의 데이터베이스 엔진과 응용 어플리케이션(=SQL 네이티브 드라이버, OLEDB 드라이버 등)이 서로 통신할 때에는 TDS(Tabular Data Stream)라는 통신 형식을 사용합니다. 프로토콜이라고 할 수도 있
kenial.tistory.com
'DB > SQL Server (MSSQL)' 카테고리의 다른 글
| [MSSQL] 인덱스 - 클러스터형 vs 비클러스터형 (0) | 2021.12.06 |
|---|---|
| [MSSQL] 데이터 저장 방식 - Page(페이지), Extent(익스텐트) (0) | 2021.12.03 |
| [MSSQL] 백업에 사용되는 기능과 옵션 (0) | 2021.11.24 |
| [MSSQL] 복구 모델(Recovery model) - Full / Bulk-logged / Simple (0) | 2021.11.24 |
| [MSSQL] 백업 종류 - Full / Differential / Transaction (0) | 2021.11.24 |








최근댓글