SQL Server라는 DBMS에 대하여 배우려고 왔는데, 갑자기 '통계'라는 내용이 나와서 당황스러울 것이다.
여기서 말하는 '통계'란 교육과정에서 배웠던 따분했던 '확률과 통계'와 같은 내용은 아니니, 안심하길 바란다!
그렇다면 MSSQL에서 말하는 통계란 무엇인지 살펴보자!
SQL Server의 통계(Statistics)란?
- 테이블 또는 인덱스 뷰에서 하나 이상의 컬럼 값들의 분포에 대한 통계 정보를 포함하는 BLOB(Binary Large Objects) 이다.
- Query Optimizer가 이러한 통계 정보를 활용하여, 쿼리결과의 *카디널리티, 행(Row)의 개수 등을 예측하고, 최적의 Query Plan을 작성한다.
=> 이러한 *카디널리티 예측치를 활용하여 Query Optimizer가 리소스를 많이 사용하는 인덱스 Scan 수행 대신 인덱스 Seek 수행을 선택함으로써 쿼리의 성능을 향상시킬 수 있는 것이다. - 각각의 통계 객체들은 하나 이상의 테이블 컬럼 리스트들을 토대로 만들어지며, 이는 히스토그램 정보, 밀도(=1/인덱스 키들의 수) 등의 상관관계 정보까지 포함한다.
*카디널리티(Cardinality) : 특정 데이터셋의 고유(Unique)한 값의 개수. (=높을수록 컬럼 값들의 중복도가 낮다는 말.)
단순히 절대적인 수치로만 보는 것이 아닌, 상대적인 값으로 보는 것이 바람직하다.
예를 들어, '성별' 컬럼의 경우 남자 or 여자이므로 이때의 카디널리티는 2이다. 주민등록번호의 경우, 테이블에 존재하는 모든 레코드가 고유하므로, 이 경우 주민등록번호라는 컬럼의 카디널리티는 해당 테이블에 들어있는 레코드의 개수가 된다.
인덱스를 사용하여 내가 원하는 데이터를 찾고자 할 때를 생각해보면, 인덱스를 활용하였을 때 최대한 많은 데이터가 걸러져 내가 원하는 데이터만 쏙쏙 골라낼 수 있는 것이 인덱스 성능이 좋다고 할 수 있을 것이다. 즉, 여러 컬럼을 동시에 인덱싱할 때, 카디널리티가 높은 컬럼(값의 중복이 적은 컬럼)을 우선순위로 두는 것이 인덱싱 전략에 유리하다는 것이다.
히스토그램(Histogram) 이란?
- 데이터셋에서 각 고유한 값의 발생 빈도를 측정하여 나타낸 것.
- Query Optimizer가 통계적 샘플링 또는 테이블 및 뷰의 모든 행(Row)에 대하여 Full Scan을 진행함으로써 컬럼값을 선택하며, 이를 통해 통계 객체의 첫번째 키 컬럼(Key Column) 값들의 히스토그램을 산출한다.
(SQL Server의 히스토그램은 통계 객체의 키 컬럼 세트에서 첫번째 열인 단일 열에 대해서만 작성됨.) - 히스토그램을 생성하기 위해, Query Optimizer는 컬럼 값들을 정렬하고, 각 고유 컬럼값과 매칭되는 값들의 개수를 계산하여 최대 200개의 인접 히스토그램 스탭(Contiguous Histogram Steps)으로 컬럼 값들을 집계한다.
히스토그램이 만들어지는 3단계
- 히스토그램 초기화(Histogram Initialization)
정렬된 데이터셋에서 첫 부분에 해당하는 값들부터 처리된다. 최대 200개의 range_high_key, equal_rows, distinct_range_rows 값들이 수집되는 단계이다. - 버킷 병합(Bucket Merge)를 통한 스캔(Scan)
정렬되어진 통계 키 리딩 컬럼(Leading column of Statistics Key)의 각 추가 값들(additional values)이 이 두번째 단계에서 처리된다. 이러한 일련의 값들은 마지막 범위에 추가되거나, 끝에 새로운 범위를 추가하여 그 범위에 추가하게 된다. 이때 새로운 범위가 형성된다면, 서로 인접한 한 쌍의 범위가 단일 범위로 병합되게 된다. 이러한 인접한 범위 쌍(1 Pair of Neighboring Ranges)이 선택되는 방식은, 정보 손실을 최소화하는 방향으로 선택되어지는데, 이때 사용되는 알고리즘이 'Maximum difference 알고리즘'이다. 이 알고리즘은 히스토그램 상의 각 스탭의 수를 최소화하는 동시에, 스탭 간 경계값들 간의 차이는 최대화 하는 전략이다. 이 단계를 거쳐 히스토그램의 스탭 개수는 적절히 병합되어 200개를 유지하게 된다. - 히스토그램 통합(Histogram Consolidation)
이 세번째 단계에서, 상당한 양의 정보가 손실되지 않는다면, 더 많은 범위(Range)들이 병합되어 스탭의 수가 최종적으로 확연히 줄어든다.
이때 히스토그램 스탭의 수가 해당 컬럼의 고유값들의 수에 비해 훨씬 적을 수 있다.(해당 컬럼의 경계값들이 200개 미만일때에도 그럴 수 있다는 것이다.)
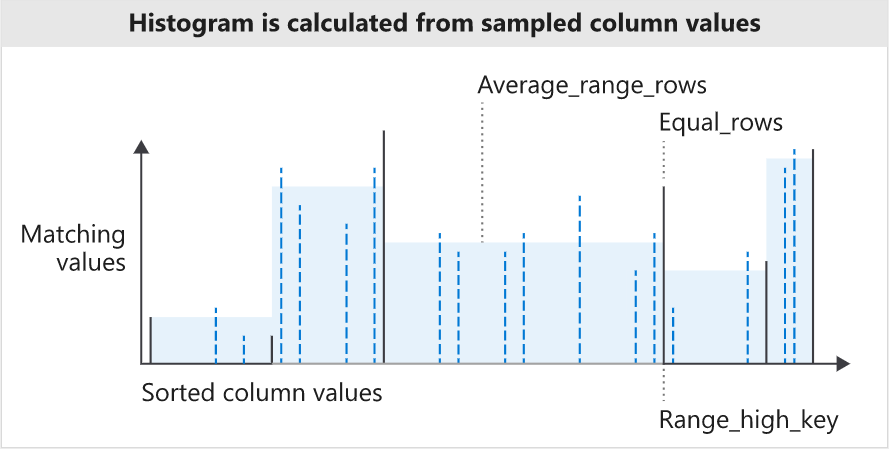
위와 같은 방식으로 데이터들을 범주화하여 효율적인 인덱싱을 할 수 있도록 하는 것이다.
밀도 벡터(Density Vector)란?
*밀도(Density) : 주어진 컬럼 또는 컬럼조합에서 데이터 중복 수에 대한 정보. 1 / (고유한 값의 개수)
=> 밀도와 카디널리티는 반비례 관계이며, 카디널리티가 높아야 보통 인덱싱을 하기 좋은 컬럼이라고 볼 수 있다.
(Unique(고유한) Value들이 많으면 인덱스를 타고 더 적은 데이터들에서 탐색하면 되므로)
밀도벡터는 아래와 같이 통계 객체에 대한 각 컬럼 조합별 밀도를 모두 포함하는 값이다.

통계 옵션(Statistics Option)
통계가 작성되고 업데이트 되는 시기 및 방법에 영향을 주는 3가지 옵션에 대해 알아보자!
이 옵션들은 DB 수준에서만 구성이 가능하다.
- AUTO_CREATE_STATISTICS
- 이 옵션이 ON으로 설정되어 있는 경우, Query Optimizer가 쿼리 구문에서 query plan에 대한 카디널리티 예상치 정확도를 높이기 위해, 개별 컬럼에 대한 통계를 필요에 따라 자동으로 생성
- 이러한 단일 컬럼 통계 객체들은 존재하고 있는 통계 객체들 중 히스토그램을 아직 가지고 있지 않은 컬럼들에 대해서 생성
- 이 옵션이 인덱스에 대해 통계가 작성될지에 대해서는 결정하지 않으며, 필터링된 통계를 생성하지도 않는다.
- Query Optimizer가 위 옵션 사용 결과로 통계를 작성하면 통계 이름이 '_WA'로 시작한다.
- 아래 쿼리를 통해 위 옵션으로 생성된 통계를 확인할 수 있음.
SELECT OBJECT_NAME(s.object_id) AS object_name, COL_NAME(sc.object_id, sc.column_id) AS column_name, s.name AS statistics_name FROM sys.stats AS s INNER JOIN sys.stats_columns AS sc ON s.stats_id = sc.stats_id AND s.object_id = sc.object_id WHERE s.name like '_WA%' ORDER BY s.name; - AUTO_UPDATE_STATISTICS
- 이 옵션이 ON으로 설정되어 있는 경우, 쿼리에 의해 통계가 사용될 때, Query Optimizer가 해당 통계가 최신인지 아닌지를 확인하여 최신이 아니라면 자동으로 업데이트 하게 됨.
- 최신인지 아닌지에 대한 기준은, INSERT, UPDATE, DELETE 구문이 수행되어 데이터가 변경된 경우, 변경된 행(Row) 개수가 임계치를 넘으면 최신이 아니라고 판정.
- '통계 재컴파일(Statistics Recompilation)' 이라고도 함.
- 인덱스 및 쿼리문에서의 단일 컬럼으로 만든 통계, 'CREATE STATISTICS'문으로 작성된 통계, 필터링된 통계 객체에 대하여 적용.
- AUTO_UPDATE_STATISTICS_ASYNC
- Query Optimizer가 통계 업데이트를 동기적으로 할지, 비동기적으로 할지 결정하는 옵션
- 디폴트는 OFF이며, 이는 Query Optimizer가 통계 업데이트를 동기적으로 하는 것을 의미
- 인덱스 및 쿼리문에서의 단일 컬럼으로 만든 통계, 'CREATE STATISTICS'문으로 만든 통계 객체에 적용됨.
- Query 컴파일이 매우 빈번하거나 통계 업데이트가 빈번하게 수행되는 워크로드의 경우, 위 옵션은 ON으로 한다면(Asynchronous Statistics 사용), Lock 차단으로 인한 동시실행(Concurrency) 문제가 발생할 수 있음. - INCREMENTAL(증분) 옵션
- 이 옵션이 ON이면, 파티션 통계별로 통계가 작성됨.
- 이 옵션이 OFF라면, 통계 트리가 삭제되고, SQL Server에서 통계를 다시 계산함. 기본값은 OFF
- 큰 테이블에서 새 파티션이 추가되는 경우, 새 파티션을 포함하도록 통계가 업데이트 되어야 하는데, 이렇게 큰 테이블에서 업데이트마다 전체 테이블 검색을 하면 시간이 오래 걸림.
따라서, INCREMENTAL 옵션을 사용하여, 파티션별로 통계를 작성 및 저장하고, 파티션이 업데이트 되는 경우 새 통계가 필요한 해당 파티션에 대해서만 통계를 새로고침함.
- 파티션별 통계가 지원되지 않는 경우에는 위 옵션이 무시되고 경고가 생성됨.
- 아래 유형은 증분 통계가 지원되지 않음.
▷ 기본 테이블을 기준으로 파티션 정렬되지 않은 인덱스를 사용하여 작성된 통계
▷ Always On 읽기 가능한 보조 DB에 대해 작성된 통계
▷ 읽기 전용 DB에 대해 작성된 통계
▷ 필터링된 인덱스에 대해 작성된 통계
▷ 뷰에 대해 작성된 통계
▷ 내부 테이블에 대해 작성된 통계
▷ 공간 인덱스 또는 XML 인덱스를 사용하여 작성된 통계
참조
Statistics - SQL Server
The Query Optimizer uses statistics to create query plans that improve query performance. Learn about concepts and guidelines for using query optimization.
docs.microsoft.com
'DB > SQL Server (MSSQL)' 카테고리의 다른 글
| [MSSQL] 통계(Statistics) (2) - CREATE, UPDATE 시기 및 통계의 효율적 활용 (0) | 2021.12.21 |
|---|---|
| [MSSQL] LSN을 활용하여 특정 시점으로 데이터 복원하기 (0) | 2021.12.10 |
| [MSSQL] 인덱스 - 클러스터형 vs 비클러스터형 (0) | 2021.12.06 |
| [MSSQL] 데이터 저장 방식 - Page(페이지), Extent(익스텐트) (0) | 2021.12.03 |
| [MSSQL] SQL Server 구조(아키텍처, Architecture) (0) | 2021.11.30 |







최근댓글